大
规
模
定
制
、
加
速
、
部
署
A
I
原
生
服
务
大
规
模
定
制
加
速
部
署
A
I
原
生
服
务
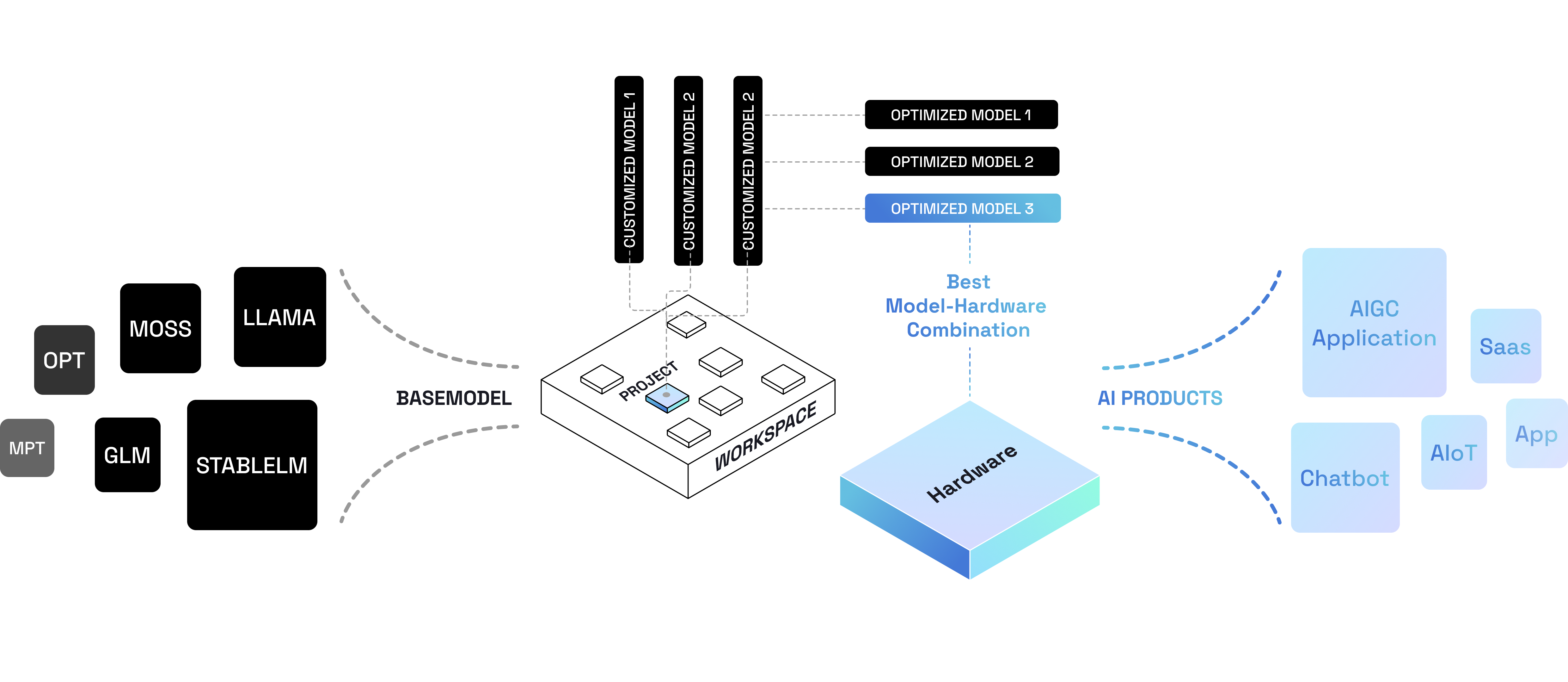
Pleiades AI是一套完整的从大模型选型、微调与开发管理、集群化部署、服务上线与管理
的企业级LLMOps平台,致力于降低大模型开发门槛和资源消耗,推动大模型的平民化。
通过降低AI应用开发的的全生命周期综合成本,帮助客户专注于自身的商业创新。
Pleiades AI是一套完整的从大模型选型、微调与开发管
理、集群化部署、服务上线与管理的企业级LLMOps平
台,致力于降低大模型开发门槛和资源消耗,推动大模
型的平民化。通过降低AI应用开发的的全生命周期综合
成本,帮助客户专注于自身的商业创新。
模型库 Foundation Models
“发现、选择和应用最适合您业务的基础大模型”
Pleiades AI 平台汇集整合了各类开源大模型,涵盖多个领域和任务类型,以满足不同业务需求

用户能够快速与大模型进行互动,无需繁琐的配置,立即开始体验和测试。深入了解大模型在不同任务上的表现,并做出相应的评估
支持对同一输入下不同模型效果的对比分析,直观地比较大模型在相同任务上的表现,辅助开发者选择最匹配其业务需求的基础大模型
平台为每个大模型提供详尽的评估标准,包括性能指标、训练数据类型、语言支持等,以便开发者能够全面了解每个模型的优势和限制

工作台 LLM Workspace
“定制、加速、规模化部署您的大模型服务”
基于选定的基础大模型,开发者可以创建并管理自己的大模型服务项目。灵活的定制化功能使开发者能够针对不同业务需求创建专属的大模型服务空间
开发者可以用自有业务数据对基础大模型进行微调,将基础大模型的能力与业务场景的特点相结合,提高模型在实际业务中的表现和准确性。同时支持开发者对模型进行精细的微调和优化,通过微调的高级参数设置,针对具体问题进行优化,精细调整模型的性能和效果
03推理 · 硬件感知优化 - 高性能、低成本、泛兼容
平台提供一系列针对不同芯片硬件(AMD、Nvidia)的优化压缩技术,可以在部署硬件上高效地释放模型性能,获得更快速、响应更迅捷的模型推理速度。实现模型推理服务的高性能、低成本、泛兼容
通过对优化后的不同硬件和模型搭配的性能和成本消耗的对比分析,了解不同硬件和模型组合的推理速度、准确性和响应时间等性能指标;比较不同配置下的硬件成本、能耗、配置规模、分布方式等。根据实际需求决策资源配置,避免不必要的资源浪费和错误的配置选择,提高资源利用率
可将基础大模型、微调模型和优化模型轻松部署为服务,在工作台内灵活调用以及测试迭代。还可以可以根据业务需求和应用场景的变化,灵活切换不同的硬件环境和资源配置,以适应业务的增长和变化
用户可以对模型服务进行全面的生命周期管理。从创建和部署到监控和维护,用户可以在一个集成的环境中管理模型服务的各个阶段。包括服务的启动和停止、版本控制、日志记录等,轻松管理、维护、拓展模型服务
平台能力
Cloud & Service
多区域
支持全球多region,选择距离业务服务最近的region进行部署,减少因为网络原因所导致的高延迟
多云支持
支持多个云厂商,可以选择一个最适合自己的云服务商进行部署,集中管理多云资源
高可靠
多可用区的多副本部署,并支持弹性伸缩,设置伸缩范围,模型将在多个可用区进行弹性伸缩
访问安全
基于TLS/SSL协议的网关,支持TCP上层的所有应用层协议进行访问控制,灵活创建授权访问,设置证书的有效期等
易运维
可视化的对基础大模型进行微调、优化、部署、监控、服务启停等操作。0基础对大模型服务做生命周期管理,并提服务接口
现在开始用Pleiades AI
构建LLM产品
现在开始用
Pleiades AI构建
LLM产品